STLM meetup: The Evolution of Database
databaseLyft Engineer, Lei Chen reviewed the evolution of databases systems in the STLM meetup. Here are the meeting notes with references and my thoughts.
The Principle
The memory hierarchy of the modern computer dictates how fast we can access the data, and how much data can be stored. The database system is designed to leverage the memory hierarchy to optimize for specialized use cases and make tradeoff between the latency, throughput, and capacity.
Single Host Database
Long long ago, the database is designed for single host due to network performance cannot compete with local storage. Using MySQL architecture as an example:
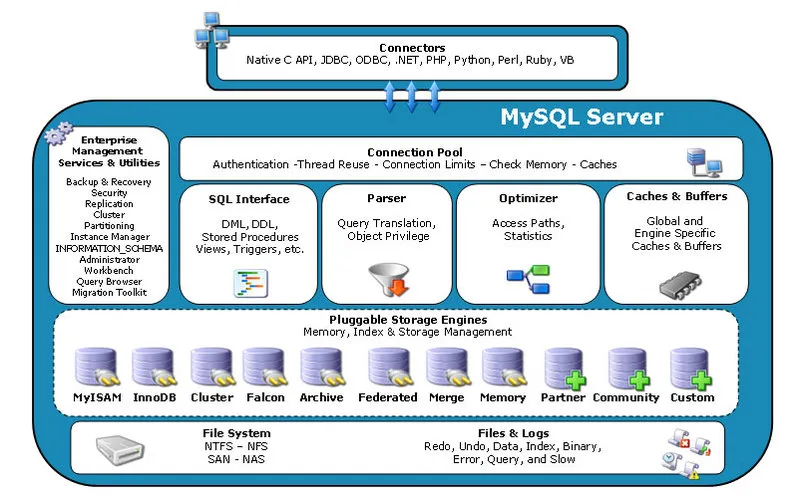
From bottom up, the MySQL composes several tiers:
- File System provided by the OS.
- Storage Engine handles the data layout to optimize for read / write or something between.
- SQL parser, optimizer, executor provides the SQL semantics.
- Connection pool manages the incoming connections, sockets, file descriptors
There several directions for the scalability:
- Separate read / write operations.
- Sharding: push the scalability problem to the business logic.
- Drop the SQL support, use key-value store instead.
- Replace the local file system with distributed file system
- Some or all of above.
Master-Slave replication
The master-slave replication separates the read / write operations:
- The master and all slaves handle the read operations.
- Only the master accepts the write operation, it then replicates to the slaves synchronously or asynchronously.1
Strong consistency requires , see the eventual consistency article .
Sharding
With sharding, we can partition the database horizontally across multiple isolated instances to improve the I/O performance. The sharding logic is either handled by a middleware or the application.
Consistent hashing is commonly used to cushion the repercussion when partition is added or removed.
Key-value store
It is not-trivial to support SQL semantics, especially transactions2, what if we drop the SQL support for scalability? Without the SQL semantics, the storage engines can be simplified as key-value stores. It is like the hash map, but the data is too big to fit into the memory3.
Hash Indexes
We can maintain a in-memory hash table to map the key to the offset of the data file. Clearly, we cannot update the value in-place, that requires us to re-index all the succeeding keys. The data file is organized as:
- append only: any
putoperation will append a new entry, and the index is updated to point to the new entry. - segmented: the data file is broken into segments, so we can compact the data file to reclaim used space, and keep the service available.
Bitcask (the default storage engine in Riak) takes this approach.
SSTable, memtable, and LSM-Tree
The hash indexes does not support range selection4, and demand all keys MUST fit into the memory. This shortcomings are addressed by the Sorted String Table, aka SSTable:
- We maintain a balanced tree in memory5, aka memtable. Once it grows bigger than the threshold, the data is persisted to a segment with sorted keys.
- The read operation first searches the memtable, then the most recent segments.
Thus, we maintain a sparse index in the memory instead of all keys. This data structure is also known as Log-structured merge-tree or LSM tree.
LevelDB and RocksDB take this approach, and HBase and Cassandra use the similar storage engine.
Distributed File System
With network speed increases, we can replace the local disks with distributed file systems, such Google File System, (see paper). There are many benefits:
- Better throughput and reasonable latency6.
- Data integrity and availability are decouple from the DB design.
Case Studies
Aurora
Amazon’s Aurora performs better than the RDS with two magic bullets (See Deep Dive on Amazon Aurora for more details):
- The underlying file system is replaced by EBS(hot data) and S3(cold data).
- The master only replicate the write-ahead log, aka WAL to avoid massive I/O.
I am kind of confused by the claim that WAL replication is more efficient; as the WAL write amplification is one of main motive that Uber engineer [migrated from pgsql to mysql][umysql-migration].
BigTable and Spanner
BigTable leverage the Google File System, SSTable, and Paxos consensus protocol (provided by Chubby?)
Spanner is built upon the BigTable, with atomic clock to ensure global consistency.
Footnotes
-
The replicate strategy is determined by the trade-off of the consistency vs. write throughput. ↩
-
The transaction MAY eat up half throughput due to locking primitives. ↩
-
You MAY find more details in Design Data-Intensive Applications, Chapter 3. ↩
-
This is by design, the hashed key MUST be randomly distributed to avoid collision. ↩
-
The BigTable uses the skip list instead of balanced tree. ↩
-
The jupiter network can deliver 1Pbps of bisection bandwidth. ↩