Learning Django by Example(2): Show me your data
django pythonIn last post, a quick-and-dirty prototype is developed to make Gelman running. In this post, I would tail the XSLT for our needs.
If you have not tried XSLT, consider the XSLT (for dummies and official reference). It is a powerful tool for data extraction. The xsl is not in the repository since we need a URI to access.
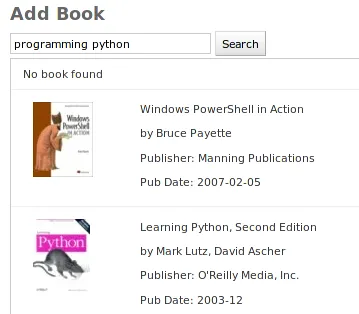
Let’s keep it simpler and more stupid. Since AWS support both ISBN query and keyword search, we could combine the two input box as one and send different requests to AWS based on the knowledge of ISBN validation. Check r12 for the implementation, here is the screenshot:
In r14, we decided to take a try of dojo.query, an alternative of jQuery; it is really cool to reference the object using CSS syntax.
dojo.forEach(dojo.query("#book_form input[@class=incoming]"), function (item) {
if (item.value != "") {
formdata.push(cache[i]);
}
i++;
});In the above code snippet, cache holds the JSON objects parsed from AWS
request, if an eBook file is attached to incoming(upload does not work now, just
use it as the mark), the corresponding meta data is collected in formdata. The
last question is how to POST it to the server?
JSON is supported in both client and server sides, i.e dojo.json and
django.utils.simplejson. In client side, we could serialize the JavaScript to
JSON string:
dojo.xhrPost({
url: dojo.byId("book_form").action,
content: { items: dojo.toJson(formdata) },
}).addCallback(function(response) { ... })And in server side, just loads the JSON string to Python objects. Check r16 for implementation.
items = simplejson.loads(request.POST['items'])Next section, we would discuss how to manipulate the database using Django’s database API.